From:https://blog.csdn.net/weixin_37947156/article/details/74435304
Scrapy github 下载地址:https://github.com/scrapy/scrapy
介绍
Scrapy是一个基于Python编写的一个开源爬虫框架,它可以帮你快速、简单的方式构建爬虫,并从网站上提取你所需要的数据。
这里不再介绍Scrapy的安装和使用,本系列主要通过阅读源码讲解Scrapy实现思路为主。
如果有不懂如何使用的同学,请参考官方网站或官方文档学习。
------------------------------------------------------------------------------------------
scrapy 中文文档 和 scrapy 英文文档参照看。因为中文文档比较老,英文文档是最新的。
scrapy 英文文档:https://doc.scrapy.org/en/latest
scrapy 中文文档:http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html
高性能爬虫 Scrapy 框架:https://www.cnblogs.com/wwg945/articles/9021888.html
------------------------------------------------------------------------------------------
简单来说构建和运行一个爬虫只需完成以下几步:
经过简单的几行代码,就能采集到某个网站下一些页面的数据,非常方便。
但是在这背后到底发生了什么?Scrapy到底是如何帮助我们工作的呢?
架构
来看一看 Scrapy 的架构图:
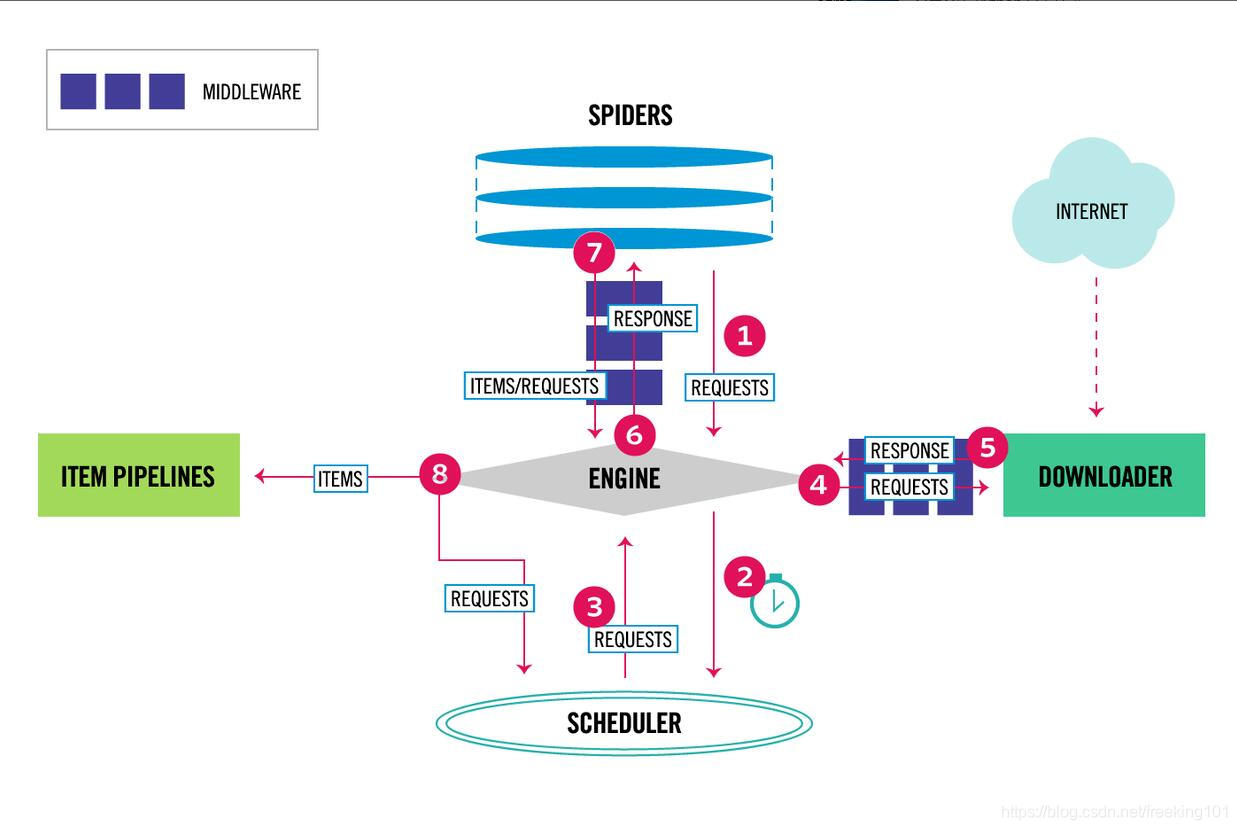
核心组件
Scrapy有以下几大组件:
除此之外,还有两大中间件组件:
数据流转
按照架构图的序号,数据流转大概是这样的:
核心组件交互图
我在读完源码后,整理出一个更详细的架构图,其中展示了更多相关组件的细节:
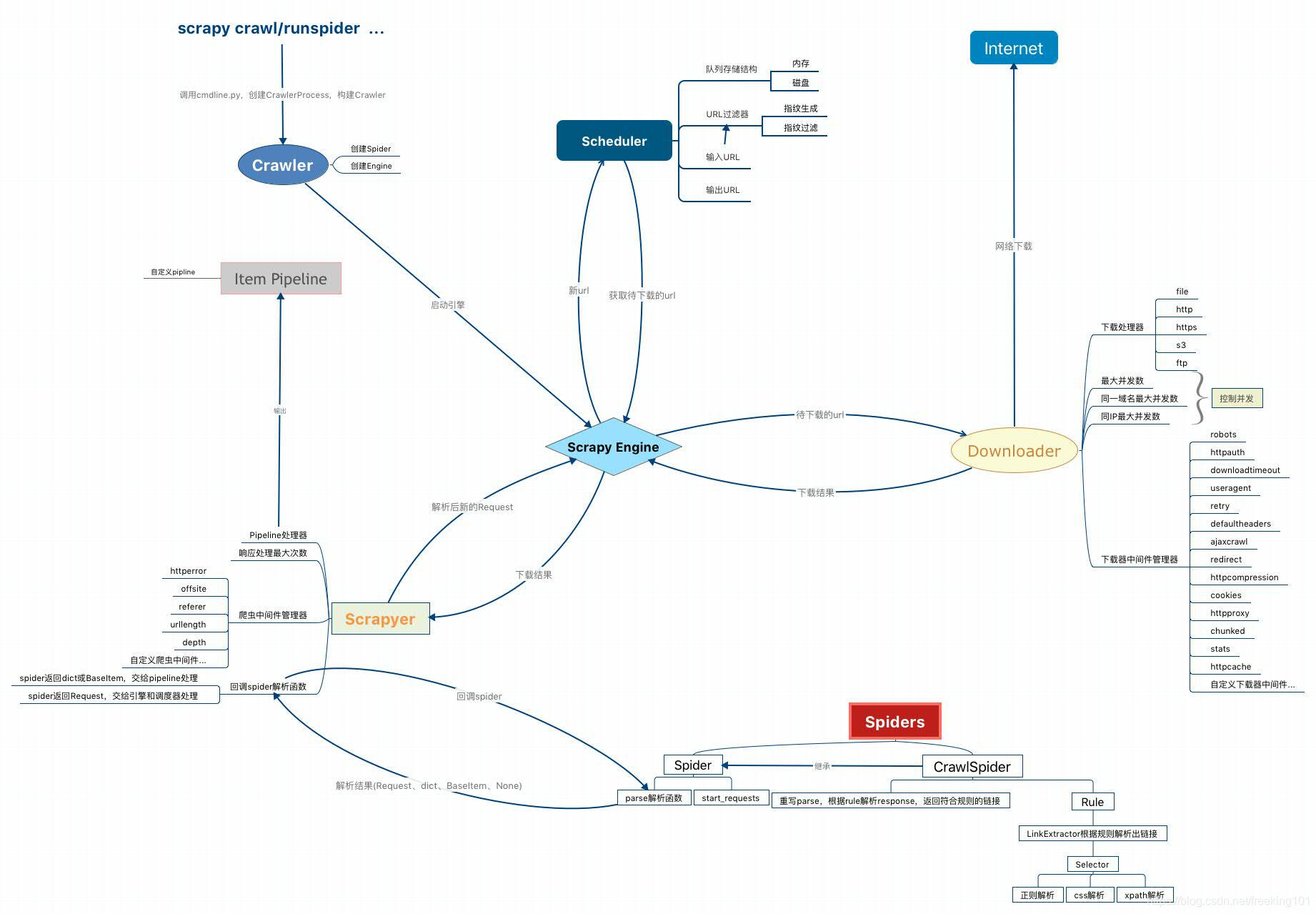
这里需要说明一下图中的Scrapyer,其实这也是在源码的一个核心类,但官方架构图中没有展示出来,这个类其实是处于Engine、Spiders、Pipeline之间,是连通这3个组件的桥梁,后面在文章中会具体讲解。
核心类图
涉及到的一些核心类如下:
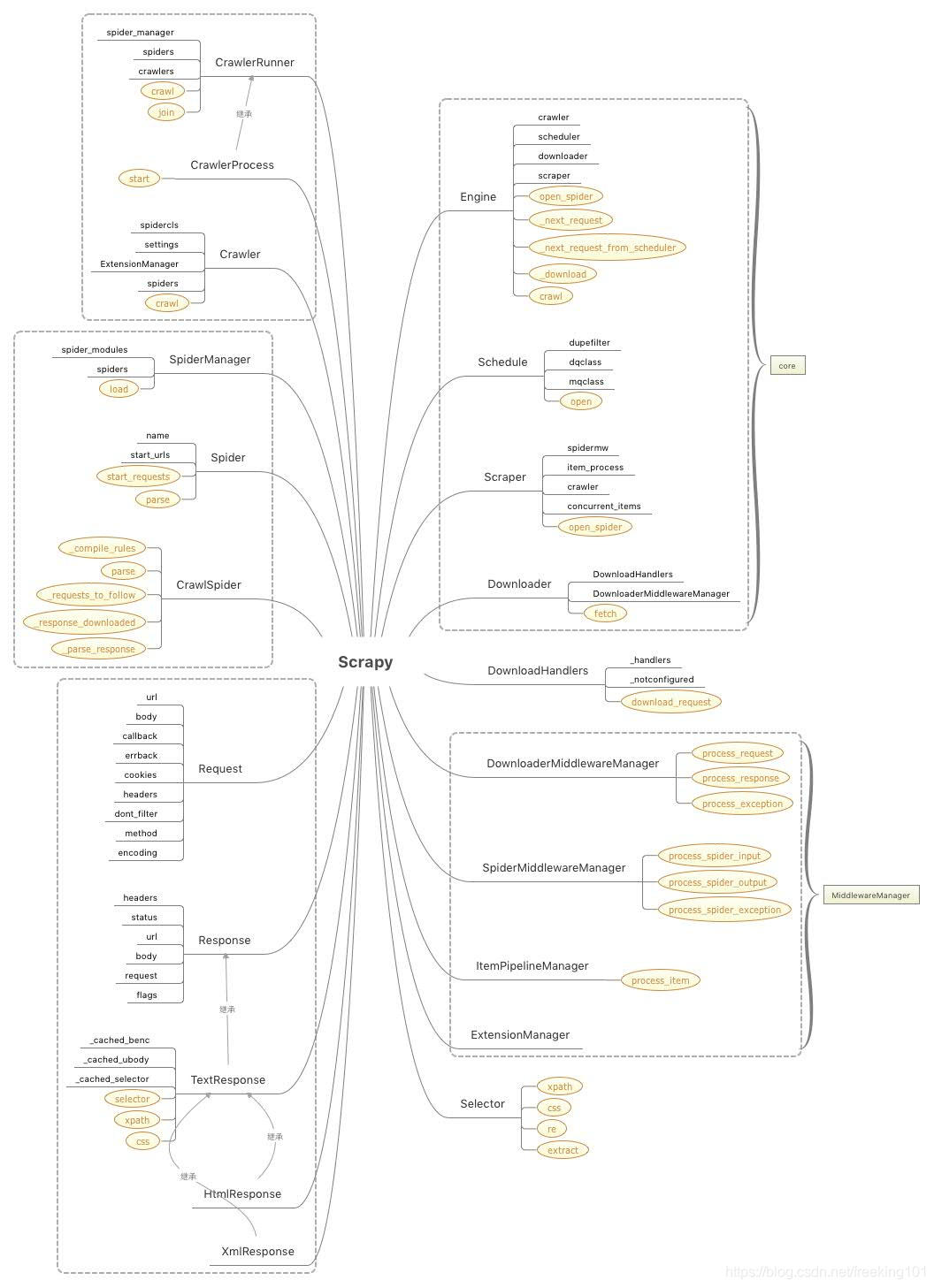
其中标没有样式的黑色文字是类的核心属性,黄色样式的文字都是核心方法。
可以看到,Scrapy的核心类,其实主要包含5大组件、4大中间件管理器、爬虫类和爬虫管理器、请求、响应对象和数据解析类这几大块。
